PGStudy-GoogleFileSystemPart
Google File System
GFS与BigTable与MapReduce的关系

GFS如何保存一个文件
先看对一个较小文件的信息保存
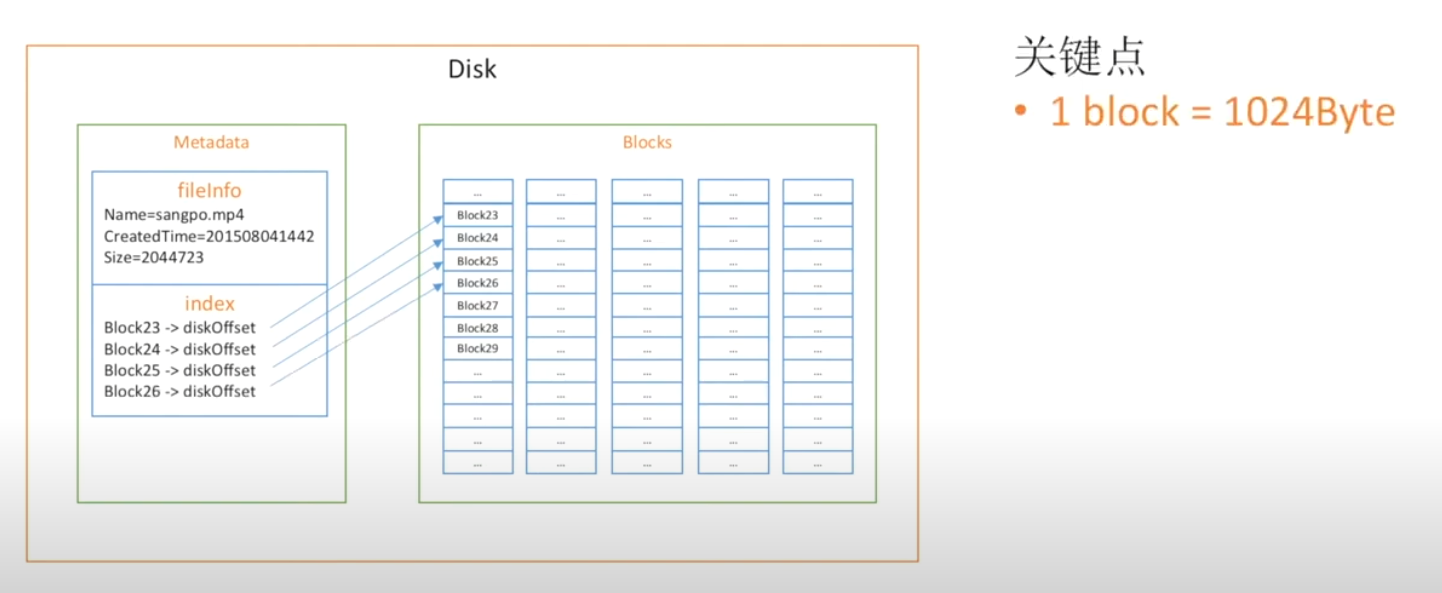
设定block为1024Byte,将一个小文件分解成非常多block,每个block都用一个指针指着
再看对一个较大的文件的信息保存
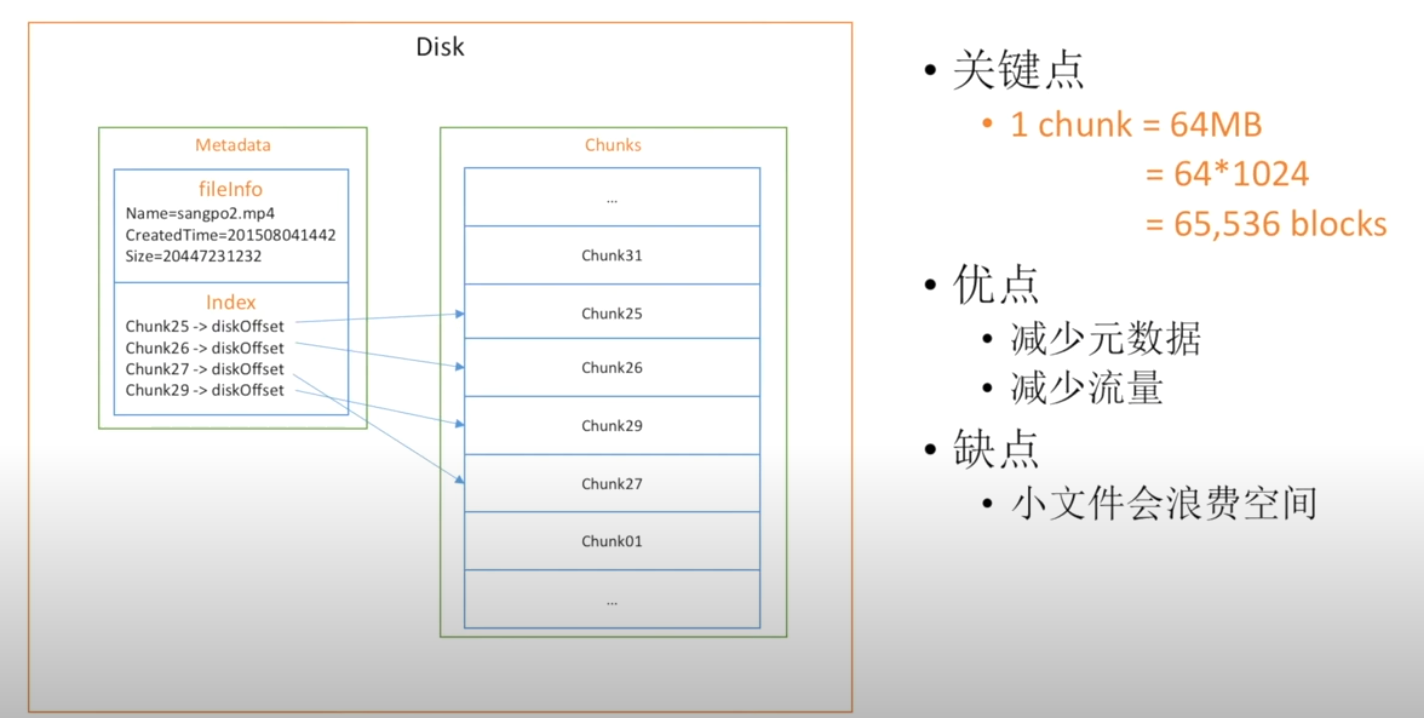
可见与小文件的逻辑是相差无几的,区别在于由block扩大到了chunk即64MB,这里的文件显然会在末尾多出64MB未使用完的额外开销
如何保存一个超大的文件
对于一个超大文件通常是无法直接在一台主机上进行保存的
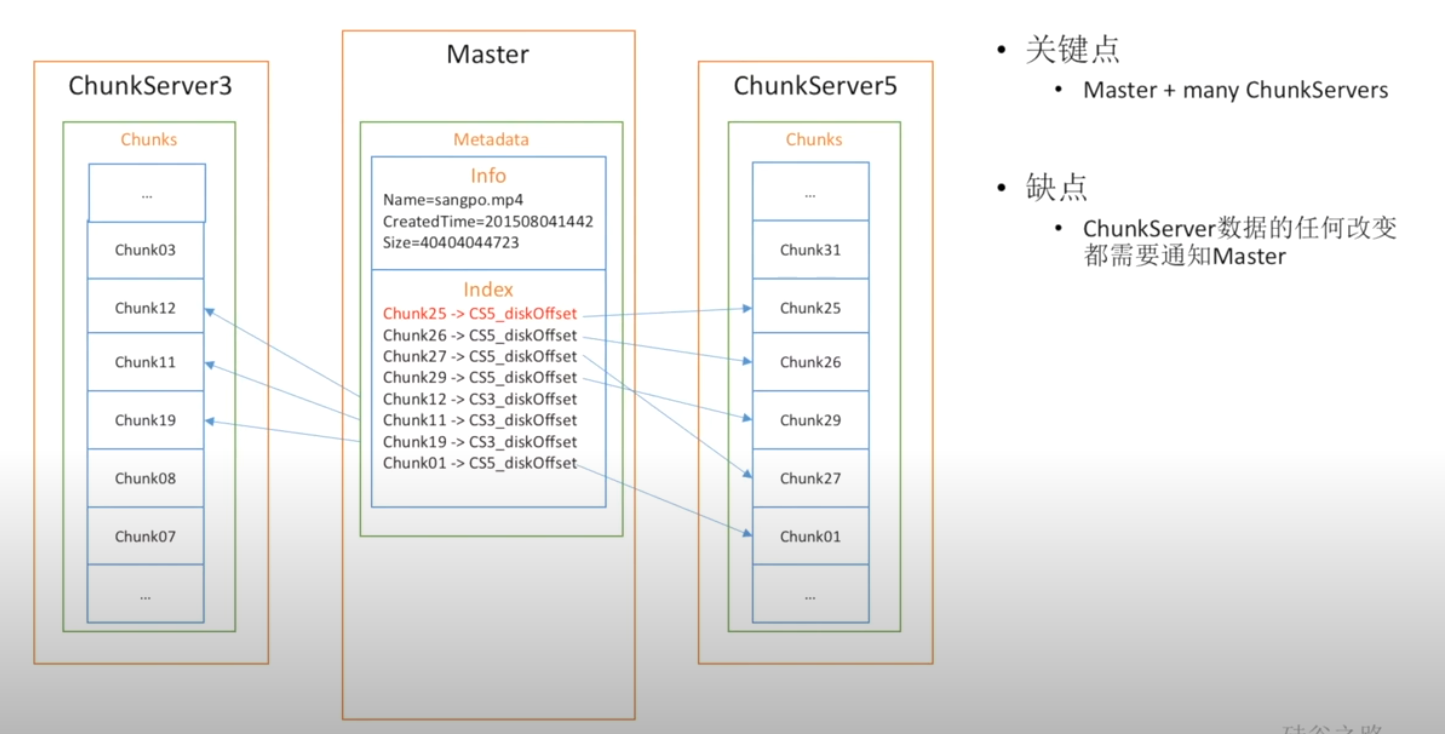
采用Master+ChunkServer组织架构保存大文件,这时缺点就出现了,对于任意的文件更改都需要ChunkSever去通知Master,产生了额外的开销
如何优化
通过将Master的索引托管到ChunkServer中即可!Master中不需要每块记录的偏移量diskOffset,只需要记住在ChunkSever中的对应Chunk即可
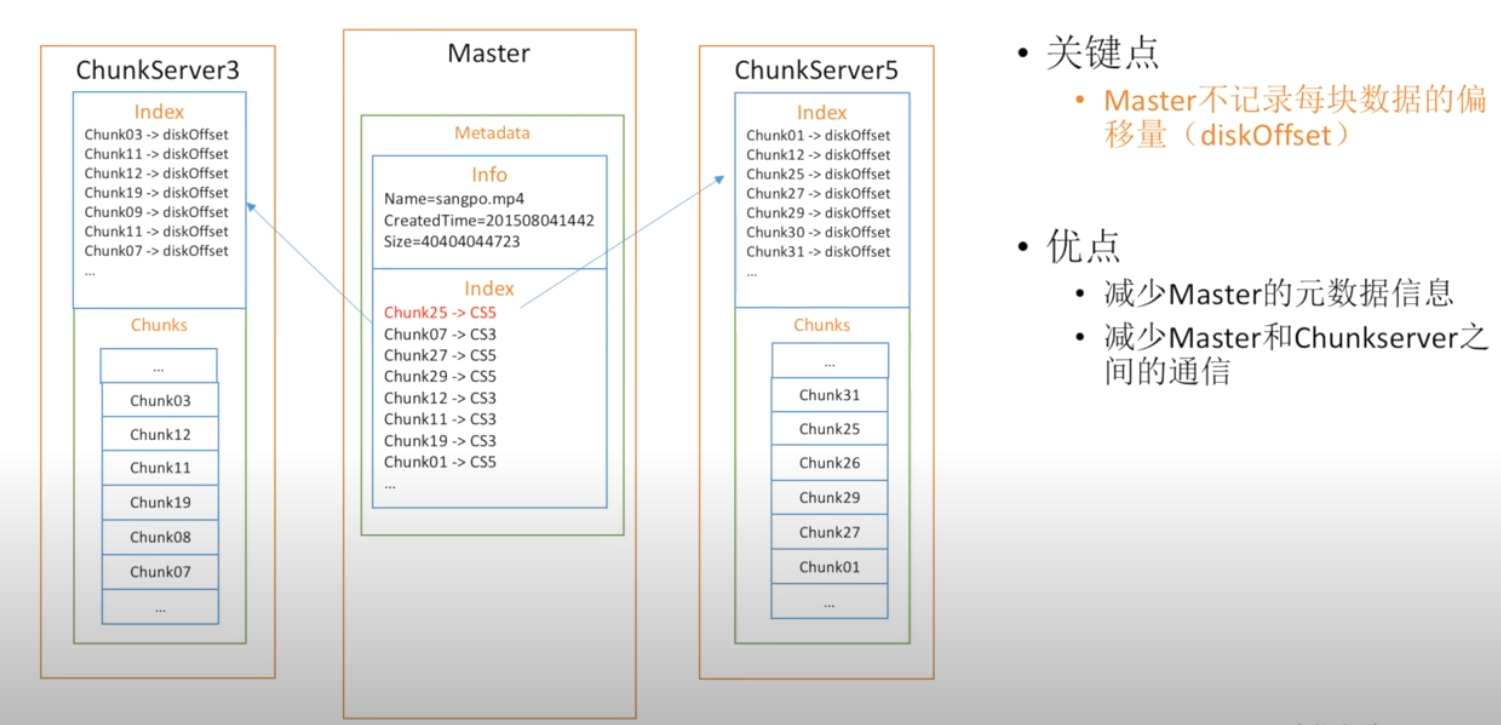
这样就减少了对MetaData (元数据信息)以及Master与ChunkSever之间的通信
如何发现文件的数据损坏

关键点
- 1 chunk = a list of blocks
- 1 block = 64kb
- block 保存 检验和 (checksum)
- 1 checksum = 32bit
- 经典文件检验和的大小 1T / 64KB *32 bit = 64 MB
如何减少ChunkSever挂掉带来的数据损失
- 创建副本——通常是3个
- 如何选择一个副本的ChunkServer
- 硬盘利用率低
- 限制最新数据块的写入流量——保证hotpot时的workbalance
- 跨机架跨中心:2+1——避免物理上的损坏
如何恢复损坏的chunk
与Master沟通,寻找最近的chunk备份
如何发现ChunkServer的Status
每隔一段时间都发一个timestamp,在业界称之为“心跳”
扩展的方式是在Masterping不通后仍然寻求其他chunkserver对不“心跳”的ping
如何应对热点hotpot
通过构建热点平衡进程
在热点平衡进程中记录以下信息
chunk的stats,通常是access frequency等
server的stats,通常是free space、free bandwidth等

通过这些信息来进行hotpot的处理
- 复制hotpot data2more chunk server
- 基于chunk server 的disk与bandwidth的情况进行select
GFS如何读一个文件
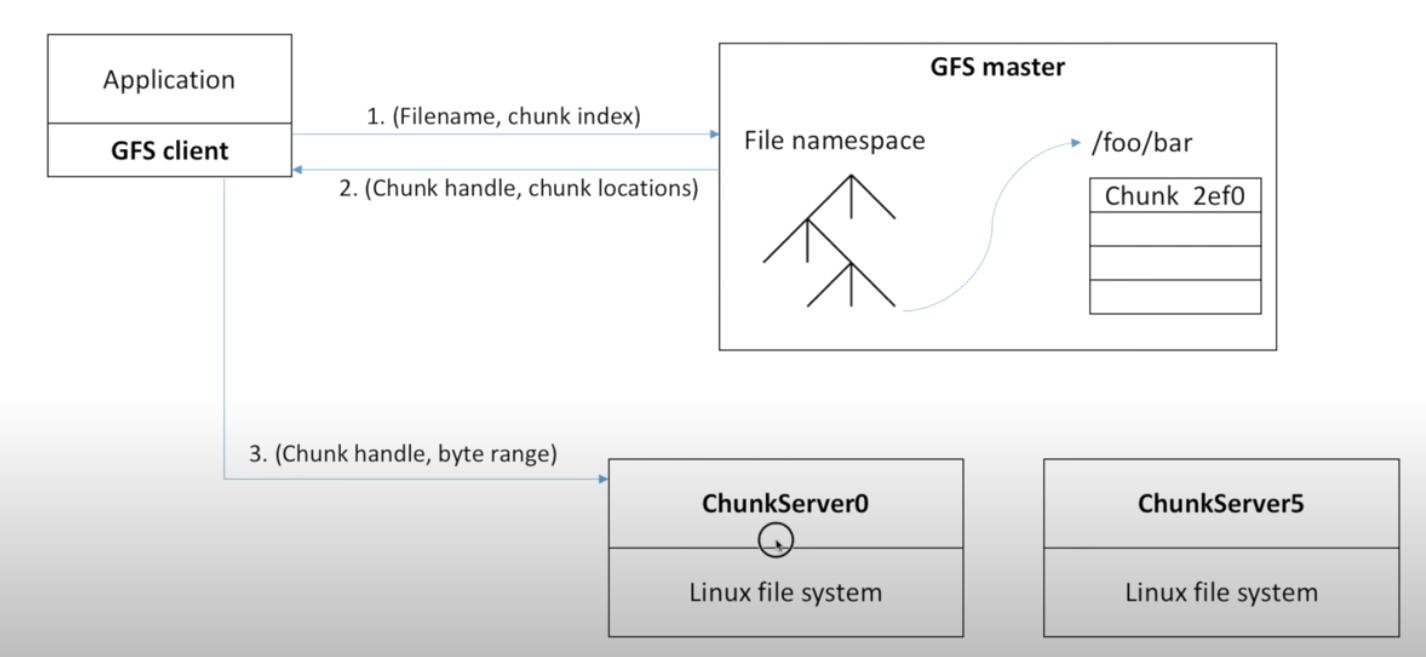
引入GFS client 客户端进程,该进程工作于Application中负责与GFSserver交互
- 与Master交互取得Handle(根据文件信息
- 与chunk server交互取得data (根据master提供的handle
GFS如何写一个文件

- Master并不负责读写,仅仅只与client交互提供文件所在信息
- master指定的primary chunk server并不是与client第一次交互的chunkserver,第一次交互的chunkserver由服务器距离远近决定
- primary chunk server仅仅指再cached后发write指令
- chunk server并不直接写入,而是先cache再写入
参考资料
- 深入浅出Google File System (youtube.com)
- Google file System paper