int ans = 1; for (int i = 1; i <= n; i ++ ) { ull r = min(i - 1, n - i); if (ans >= r || get(ph, i - ans, i - 1) != get(rh, n - (i + ans) + 1, n - i)) continue; while (ans <= r && get(ph, i - ans, i - 1) == get(rh, n - (i + ans) + 1, n - i)) ans ++ ; ans -- ; } cout<<"Case " << ++t<<": "<<ans<<endl; } }
ull ans = 1; for (int i = 1; i <= n; i ++ ) { ull r = min(i - 1, n - i); if (ans >= r || get(h1, i - ans, i - 1) != get(h2, n - (i + ans) + 1, n - i)) continue; while (ans <= r && get(h1, i - ans, i - 1) == get(h2, n - (i + ans) + 1, n - i)) ans ++ ; ans -- ; }
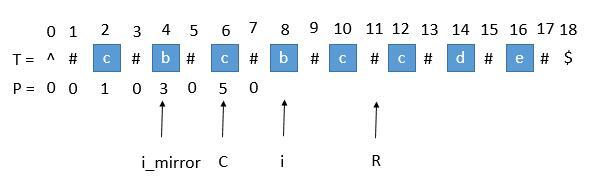
// 马拉车算法 public String longestPalindrome2(String s){ String T = preProcess(s); int n = T.length(); int[] P = newint[n]; int C = 0, R = 0; for (int i = 1; i < n - 1; i++) { int i_mirror = 2 * C - i; if (R > i) { P[i] = Math.min(R - i, P[i_mirror]);// 防止超出 R } else { P[i] = 0;// 等于 R 的情况 }
int f=lca(a,b); int p1=((rh[a]-rh[fa[f]]*qmi(p[depth[f]-1],MOD-2,MOD)%MOD)+MOD) %MOD; int p2=(ph[b]-ph[f]*p[depth[b]-depth[f]]%MOD+MOD)%MOD; int ans1=(p1*(p[depth[b]-depth[f]])%MOD+p2)%MOD; p1=(rh[b]-rh[fa[f]]+MOD)%MOD*qmi(p[depth[f]-1],MOD-2,MOD)%MOD; p2=(ph[a]-ph[f]*p[depth[a]-depth[f]]%MOD+MOD)%MOD; int ans2=(p1*(p[depth[a]-depth[f]])%MOD+p2)%MOD; cout<<(ans1==ans2?"YES\n":"NO\n"); cout<<f<<endl; cout<<ans1<<' '<<ans2<<nline; } }