OSDI24-ServerlessLLM: Low-Latency Serverless Inference for Large Language Models
OSDI24-ServerlessLLM: Low-Latency Serverless Inference for Large Language Models
Overview
这个系统模块通过对输入token以及模型参数进行分片的方式,以及一种特殊的overlap的请求抢占方式构建基于局部性与大量本地异构内存的推理延迟优化方案。
Backgroud
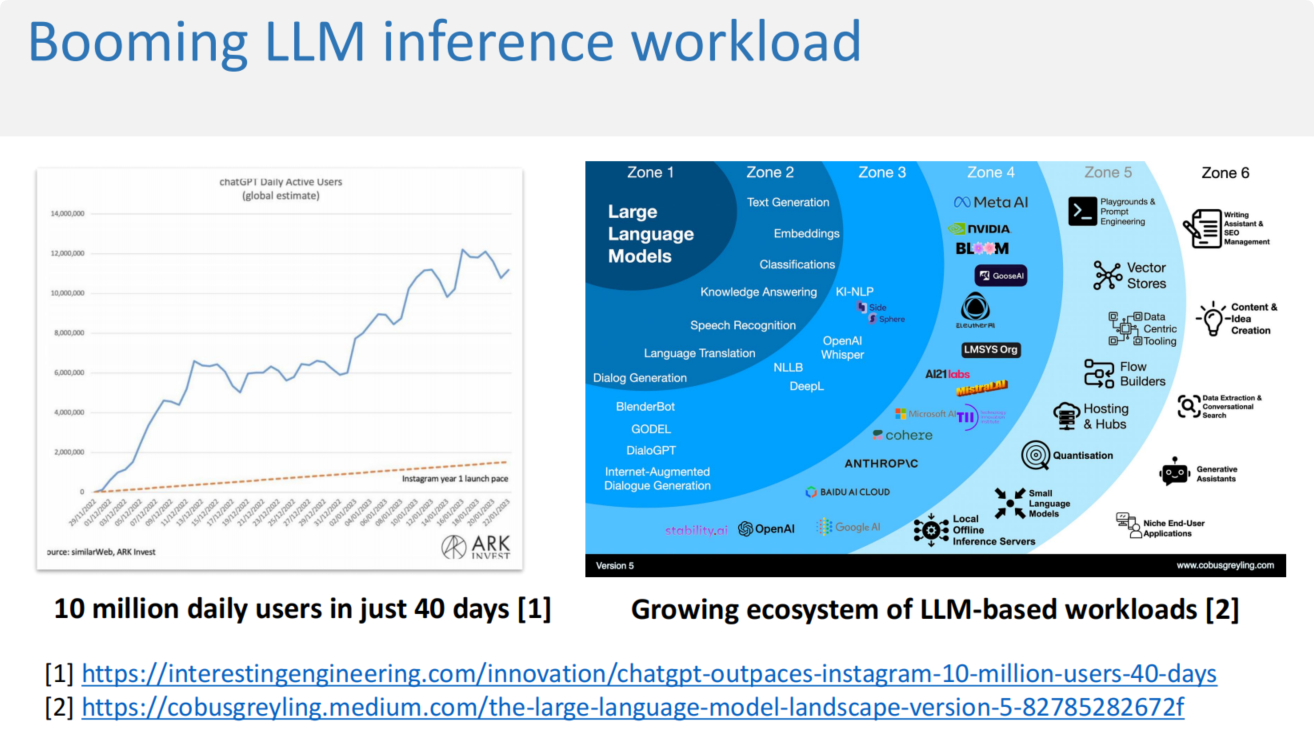
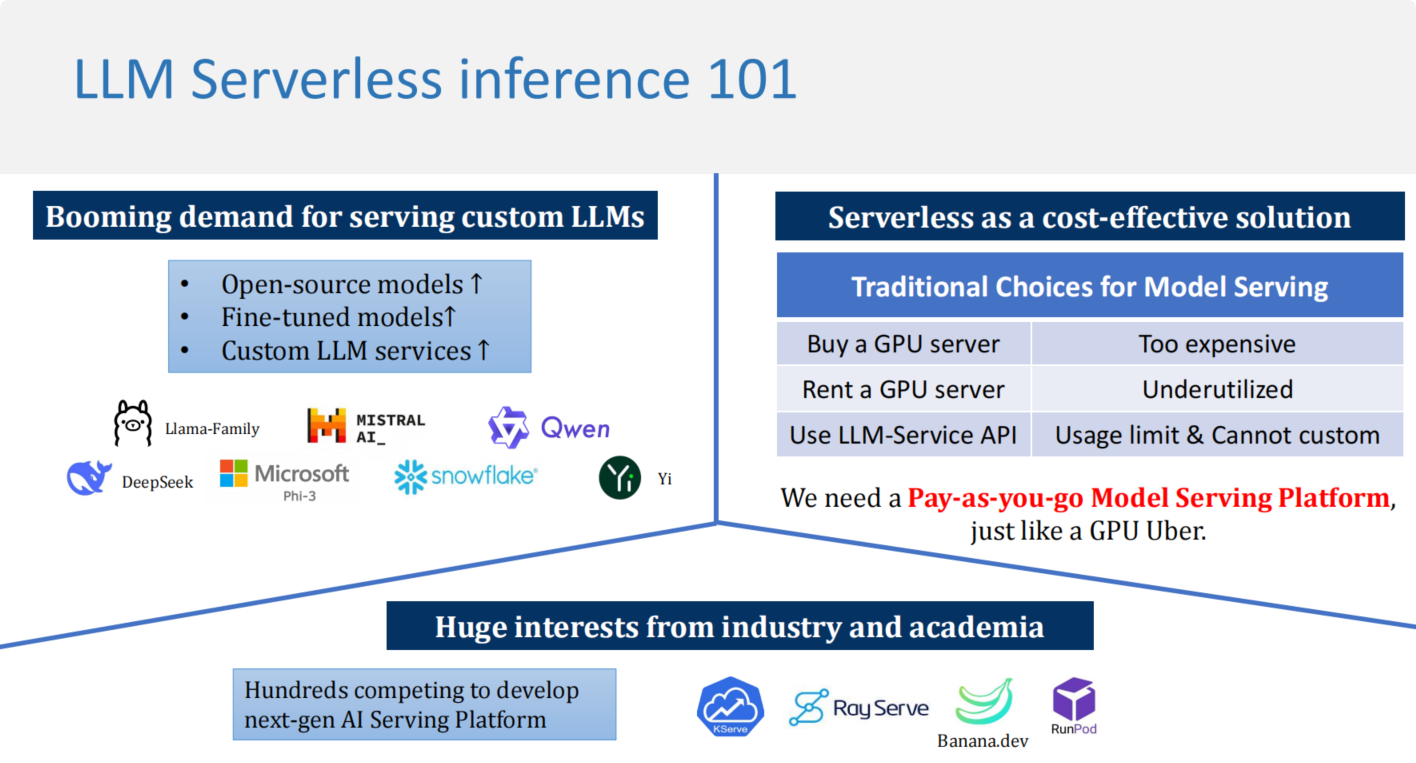
随着大模型运用逐渐广泛,对不同模型部署的需求也越来越多,包括开源,微调和定制化的模型服务。在现有的服务中,购买GPU服务器是最直接的方式,但这样的成本过于昂贵,租借服务器又会有利用不充分的问题,使用API则无法满足大模型的定制化服务。因此业界都在关注如何使用GPU算力集群去做下一代的AI平台的推理部署,即serverless clusters。
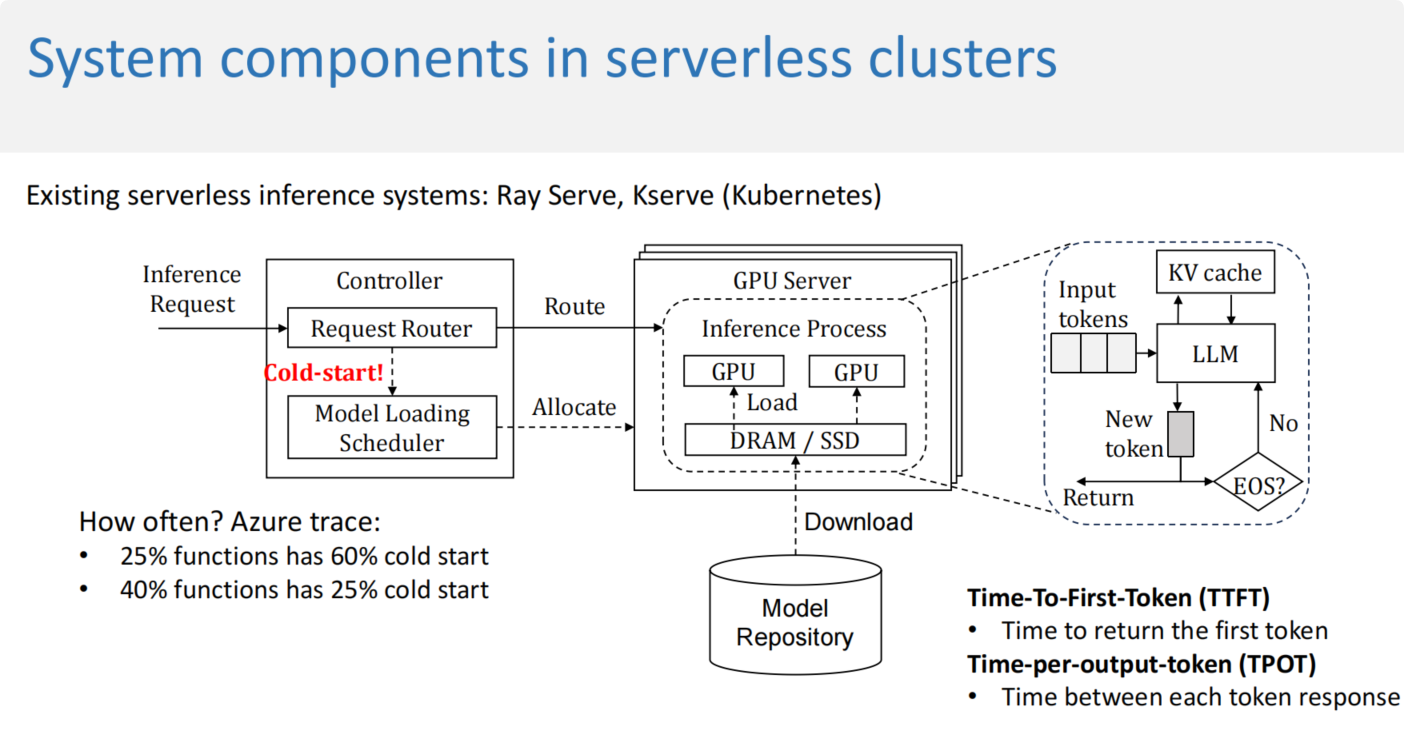
这张图说明25%的函数有60%的冷启动开销,另外有40%的函数有25%的冷启动开销,给出了两个性能指标定义TTFT,TPOT,两个极其重要的推理性能指标,分别描述“首次响应时间”,“间隔响应时间”。
Main Idea
- 假设本地空间足够大能够尽可能的去存储模型
- SSD的带宽在模型加载中没有被完全利用
- 通过结构化并行传输数据与模型推理迁移的方式拉高吞吐量和整体效率
The root principle
优化从SSD到DRAM以及GPU中的数据传输,通过模型迁移策略提高整体的推理效率。
冷启动友好的ckpt加载

异步进行模型初始化与多层的二进制数据(参数与token)加载。并在最后进行同步。
这里定义了Tensor index file,通过结构化加载的二进制数据做pipeline并行。
异构加载模型

 这里采用四种方式,最终将效率提高了5-8倍,在Mini-IO、SATA-SSD下优化表现不是很明显,但在NVMe中表现显著,这是由于Pytorch与safetensor的方式并没有完全利用NVMe的带宽容量。
这里采用四种方式,最终将效率提高了5-8倍,在Mini-IO、SATA-SSD下优化表现不是很明显,但在NVMe中表现显著,这是由于Pytorch与safetensor的方式并没有完全利用NVMe的带宽容量。
这里有几点需要注意:
- 有前面划分数据的方式才会有后面可行的优化方式,例如pipeline并行就需要严格的数据划分。(异步下的同步操作)
- 数据的划分是在远端服务器(数据本身)就已经做好的,因此才能被
model load scheduler调度
推理迁移

这里说明了为什么设计抢夺式的推理是整体更优的。
就是一个原因,加载模型和迁移的操作是异步的,通过抢夺式设计可以预先加载模型,然后迁移模型的推理。
这里有两点值得注意:
- 推理时在另一台服务器加载模型本身是有开销的,它需要占用显存,置换了这个位置原本应有的模型,可能对后续的模型推理造成影响。但也可以说这是一种“预测”操作
- 这种迁移的操作建立在迁移开销非常小的基础上。(事实上可以通过迁移token并异步计算kv-cache的方式去做迁移,也确实能达到这个效果)
详情可以看silde中的动画效果,做的还是不错。
有效的“热”迁移
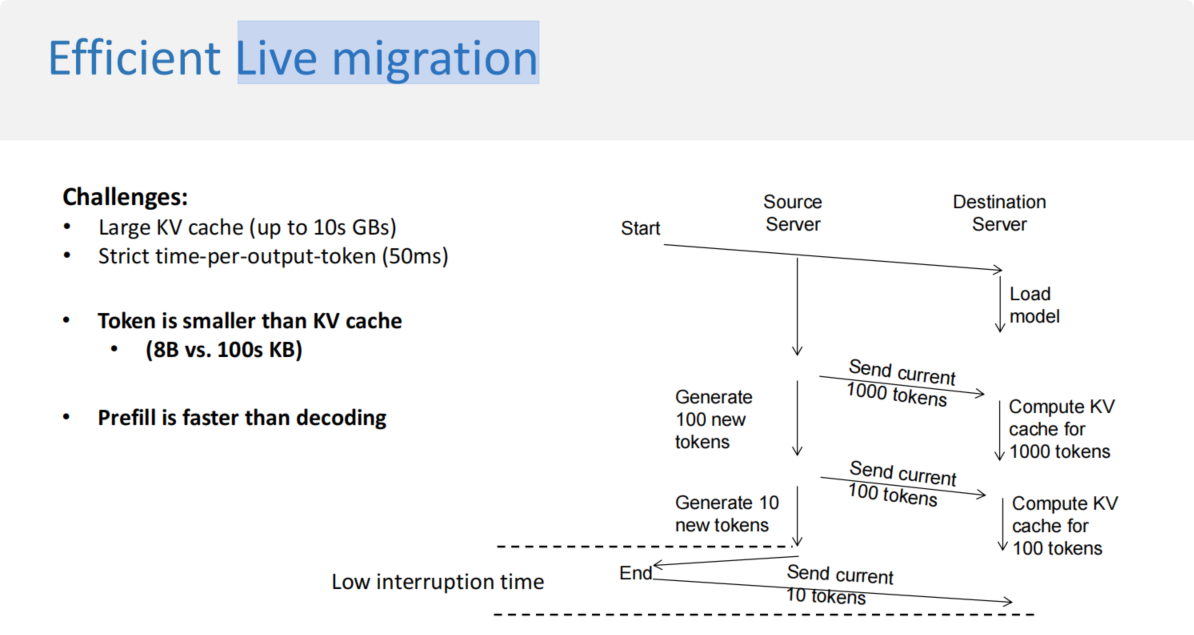
kv-cache相当大(大于10GB),因此直接迁移kv-cache的操作不合理,其次TPOT的实践需要做到非常小(50ms),因此迁移的操作需要做到成本很低。启发是profill要远比decoding要快,不能直接迁移kv-cache而可以在加载模型后做一个kv-cache的异步计算,减少最后迁移时的冲突开销。
模型存放策略

最后介绍了在单卡A100上的模型分配操作,总体思想是两种选择,从DRAM中加载与从SSD中加载,认为从SSD中加载的方式由于DRAM抢占GPU原有模型。
实验

在$4\times 4$的a40集群上进行的实验遥遥领先。