OSDI18-A Distributed Framework for Emerging AI Applications
Ray: A Distributed Framework for Emerging AI Applications
Read Motivate
由ServerlessLLM: Low-Latency Serverless Inference for Large Language Models作为对比标准引入。[Ray的官方Github仓库](ray-project/ray: Ray is an AI compute engine. Ray consists of a core distributed runtime and a set of AI Libraries for accelerating ML workloads.)Star数已有38k(截至2025年9月)。由UC Berkeley的RISELab发布,国内主要是蚂蚁在用。
Introdaction
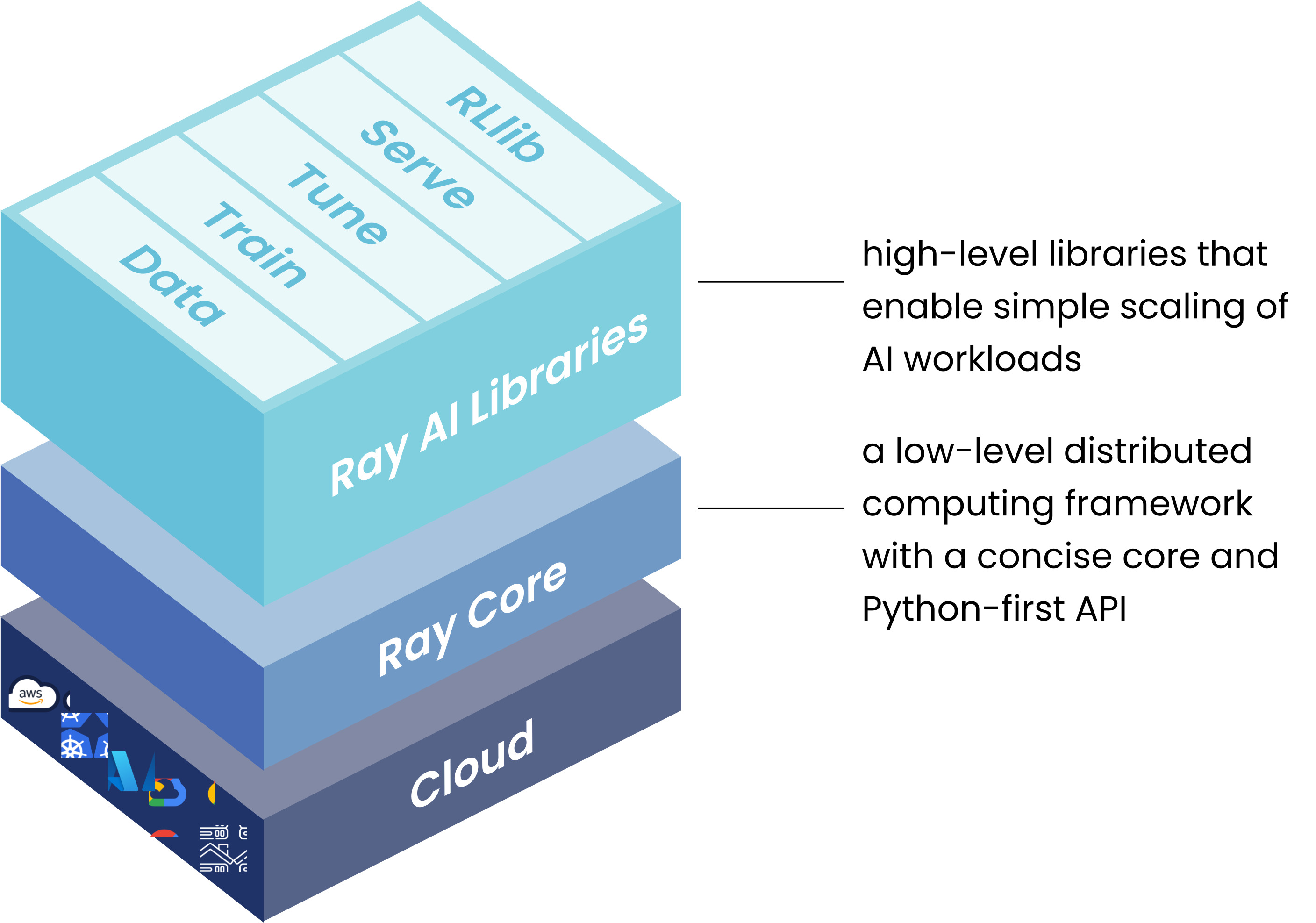
Ray是一个分布式计算框架系统,为现代AI应用而设计。在论文中Ray的设计的经典应用场景为强化学习(RL)的三个过程Simulation、Train,Serving而设计。时至今日,Ray适用于任何分布式计算的任务包括分布式训练,目前支持库包括超参数调优Ray tune,梯度下降Ray SGD,推理服务RaySERVE,分布式数据Dataset以及分布式增强学习RLlib,详情如下图。
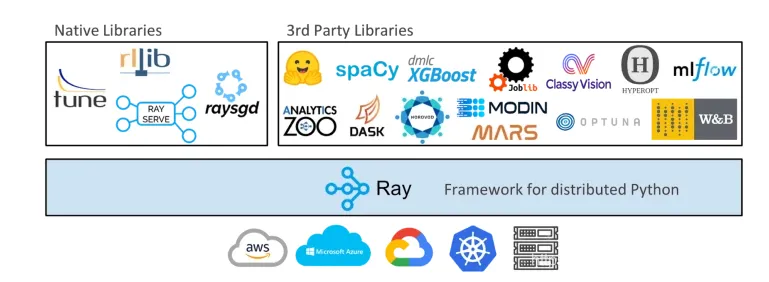
在Ray论文的slide中,Overview这么介绍Ray面对的需求。
- 足够灵活:在功能,可用和资源类型上需要足够灵活
- 高效:在程序调度上必须保持高效
- 易于维护:程序必须拥有足够的故障容错和健壮性

Motivation
文章首先从过去的两个十年(18年)讲起,谈到许多组织对大量数据的收集和利用,导致了大量批处理,流处理,图像处理的框架开发。对大量数据级的分析是这些框架的核心部分,引领了“大数据”时代的起始。
而监督学习作为当下最主流的ML范式之一,在监督学习中,每一条数据都对应着一个相对应的标签,监督学习的目的是构建一个能够将数据映射为标签的模型,其中最主流的模型之一是深度神经网络,而深度神经网络的复杂性(不可解释,复杂的大结构)导致为其服务的框架(TensorFlow,MXNet,pyTorch等)都专注于利用硬件(GPU\TPU\NPU)加速神经网络的运行。然而AI的前景要远比监督学习任务宽泛。
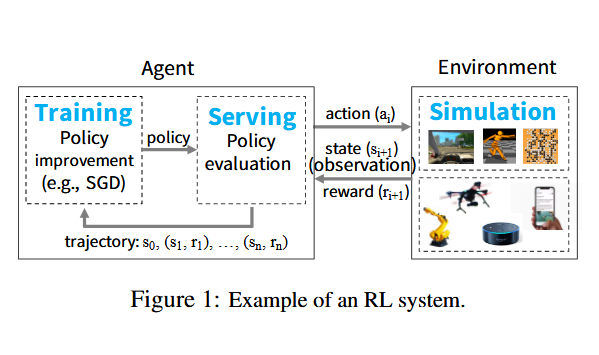
Ray的设计者认为,下一代的AI应用将与环境存在持续、连续的交互,并从交互的反馈中学习,这naturally framed into Reinforcement Lreanings——在一个不确定的环境中,根据有限的,非严格实时的信息调整policy,并达成目标。这要求达成三个目标:
- Simulation:通过给定(随机)的policy在环境中的模拟评估一个策略并给出相应的反馈,使智能体能够了解到选择(action)对任务的短长期影响
- Train:分布式训练。这一点与传统的监督学习相似。策略的改进通常是由分布式的GPU集群进行的深度神经网络的方法进行的。其中使用的数据就来自SImulation。
- Serving:通过将policy作为服务部署,应用于交互式的闭环或开环场景上。
为满足RL、超参数微调,分布式训练的需求,设计框架必须满足如下图所示的key features
- 不同类型,并发的计算
- 动态的任务拓扑图
- 高吞吐量(Task and Object)与低延迟
- 透明的故障容错基址
- 任务并行和actor programming models( 带状态的执行者编程模型)
- 横向的扩展性(能够在大规模的CPU与GPU集群上保持线性的稳定性能增长)

现有的框架,例如MapReduce、Apache Spark、Dryad批处理同步并行系统用于分布式训练并不支持细粒度的模拟或policy部署。CIEL、Dask任务并行框架缺少了部分对分布式训练和服务的支持。而流系统也是一样。而分布式的深度学习框架则不原生支持模拟和服务。最后模型服务例如TensorFLow Serving和Cliper不支持训练和模拟
Bulk-synchronous parallel systems such as MapReduce [20], Apache Spark [64], and Dryad [28] do not support fine-grained simulation or policy serving. Taskparallel systems such as CIEL [40] and Dask [48] provide little support for distributed training and serving. The same is true for streaming systems such as Naiad [39] and Storm [31]. Distributed deep-learning frameworks such as TensorFlow [7] and MXNet [18] do not naturally support simulation and serving. Finally, model-serving systems such as TensorFlow Serving [6] and Clipper [19] support neither training nor simulation.

虽然通过缝合现有的系统可以开发端到端的解决方案或者像AlphaGo一样开发单独的系统。但这样的方案带来了巨大的系统工程的负担。
Horovod [53] for distributed training, Clipper [19] for serving, and CIEL [40] for simulation
因此需要一个分布式计算框架,用于支持异构的计算资源,不同层级的执行任务,动态的计算图,并在毫秒级的延迟下分布式处理百万级别的任务数量。
Architecture
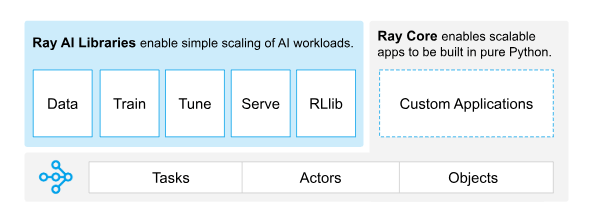
Ray在如今的简易架构图如下,如今的Ray由 Ray Core 和 Ray AI Libraries 两部分组成,拥有丰富的生态系统。
RayCore
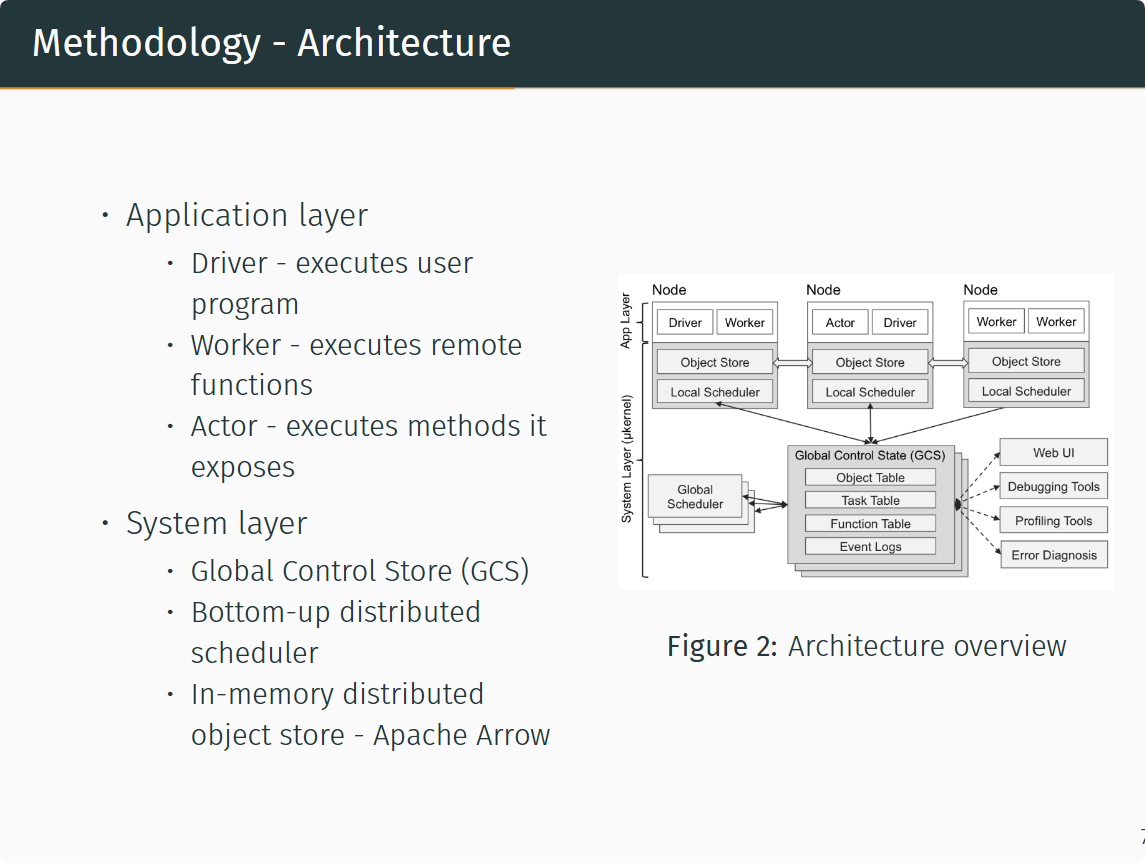
Ray的系统架构分为两个部分Application Layer和System Layer。
其中Application Layer包含三种不同进程 Driver, Worker , Actor。分别用于执行用户程序,接受源自driver或其他worker的任务的无状态进程,由Worker或Driveer现实实例化连续执行函数的有状态进程。其中worker是自动创建并且被系统层指派任务,并且当一个远端函数被声明时,该函数会将被自动发布给所有worker,worker顺序执行任务,并不维护本地状态。Actor执行时进调用其公开的函数,每个函数的执行都取决于前一个函数的返回状态。
- Driver: A process executing the user program.
- Worker: A stateless process that executes tasks (remote functions) invoked by a driver or another worker. Workers are started automatically and assigned tasks by the system layer. When a remote function is declared, the function is automatically published to all workers. A worker executes tasks serially, with no local state maintained across tasks.
- Actor: A stateful process that executes, when invoked, only the methods it exposes. Unlike a worker, an actor is explicitly instantiated by a worker or a driver. Like workers, actors execute methods serially, except that each method depends on the state resulting from the previous method execution.
而 System Layer 同样包含三种不同的设计。Global Control Store (GCS) 、Bottom-up distributed scheduler、In-memory distributed object store - Apache Arrow。GCS是一个key-value store的pubsub全局控制器,存储所有Object的元数据位置同时采用分片实现规模化,并用分片链复制提供故障容忍。Bottom-up distributed scheduler是一种调度设计,它通过设置多个Global Scheduler与Local Scheduler(单node单个)消除了调度器在高并发低延迟的分布式任务中的瓶颈。In-memory distributed object store - Apache Arrow是一种以Apache Arrow数据格式存储的零拷贝数据共享机制,用于在统一节点的任务之间进行数据交换。
The global control store (GCS) maintains the entire control state of the system, and it is a unique feature of our design. At its core, GCS is a key-value store with pubsub functionality. We use sharding to achieve scale, and per-shard chain replication [61] to provide fault tolerance. The primary reason for the GCS and its design is to maintain fault tolerance and low latency for a system that can dynamically spawn millions of tasks per second.
Application Layer
-
Ray的核心API(部分
代码 说明 futures = f.remote(args) 远程地执行函数f。f.remote()以普通对象或future对象作为输入,返回一个或多个future对象,非阻塞执行。 objects = ray.get(futures) 返回与一个或多个future对象相关联的真实值,阻塞执行 ready_futures = ray.wait(futures, k, timeout) 当futures中有k个future完成时,或执行时间超过timeout时,返回futures中已经执行完的future actor = Class.remote(args) futures = actor.method.remote(args) 将一个类实例化为一个远程的行动器,并返回它的一个句柄。然后调用这个行动器的method方法,并返回一个或多个future. 两个过程均为非阻塞的。 -
Drvier在此处不过多赘述。
-
Task,指在无状态的工作器(worker)中执行的远程函数。远程函数被调用时会立即返回一个future对象,而真正的返回值可以通过ray.get(<future对象>)的方式来获取。或通过wait等待部分future完成。
任务的编程范式如下:
- 注册任务:在需要注册为任务的函数上加上@ray.remote装饰器
- 提交任务:在调用具有@ray.remote装饰器的函数时,需要带上.remote()而不是直接调用
- 非阻塞提交:无论任务的运行需要多少时间,在提交任务后都会立即返回一个ObjectRef对象
- 按需阻塞获取结果:在你需要函数的返回值时,可以通过ray.get来获取
# 全流程eg @ray.remote def f(x): return x * x object_ref = f.remote(2) assert ray.get(object_ref) == 4任务是无状态的,任务所操作的对象都可以看作不可变对象(Immutable Objects),或者任务调用可以看作一个无副作用的(Side-effect Free)表达式,任务的输出(返回值)仅与输入(实参)有关。
Remote functions operate on immutable objects and are expected to be stateless and side-effect free: their outputs are determined solely by their inputs. This implies idempotence, which simplifies fault tolerance through function re-execution on failure.
# 声明两个功能相同的函数,一个是Ray任务,另一个是普通的Python函数 @ray.remote def append_one(container): container.append(1) return container def local_append_one(container): container.append(1) return container container = [] object_ref = append_one.remote(container) result = ray.get(object_ref) # 此处可确保函数已经在远程执行完成 print(result) # [1] print(container) # []; 远程函数未对container产生副作用 local_append_one(container) print(container) # [1]; 本地函数对container产生了副作用这样设计的优点是能在函数执行出错时自动重新执行函数(因为不依赖于其他任务,可以在任意时候独立地执行),以提高容错性;缺点是限制了函数对全局变量或内存引用的访问。任务的设计使得Ray具备以下能力:
- 细粒度负载均衡:利用任务级粒度的负载感知调度来进行细粒度的负载均衡
- 输入数据本地化:每个任务可以在存有它所需要的数据的节点上调度
- 较低的恢复开销:无需记录检查点或恢复到中间状态
@ zhihu liadrinz
-
Actor,行动器用来表达有状态的计算任务。每个行动器都会暴露一些可供远程调用的方法,类似于任务中的远程函数,不同的是,使用f.remote顺序地提交若干个远程函数后,这些函数是并行执行的,但在同一个actor下使用actor.method.remote顺序地提交若干个远程方法后,这些方法将串行地执行。但是,不同actor之间的调用是可以并行的。可以用一个图来描述任务和行动器的区别和联系:

行动器的编程范式如下:
- 注册行动器:在需要注册为行动器的类上加上@ray.remote装饰器
- 实例化行动器:相比于普通Python类的实例化,需要在类名后加上.remote
- 提交方法调用:调用行动器的方法时,同样需要带上.remote()而不是直接调用
- 非阻塞提交:无论方法的运行需要多少时间,在提交任务后都会立即返回一个ObjectRef对象(同一行动器实例下,方法会按照提交顺序串行地运行)
- 按需阻塞获取结果:在需要方法运行的返回值时,可以通过ray.get来获取
# 全流程eg @ray.remote class Counter(object): def __init__(self): self.value = 0 def increment(self): self.value += 1 return self.value counter = Counter.remote() refs = [] for i in range(10): ref = counter.increment.remote() refs.append(ref) for i, ref in enumerate(refs): assert ray.get(ref) == i + 1行动器的设计使得Ray具备更高效的细粒度更新能力。因为行动器是一种高内聚的设计,状态与可能改变状态的操作被设计在一个类中,使得这些操作不依赖于外界的状态,从而在更新状态时省去了许多序列化和反序列化的开销。一个例子是使用行动器来实现参数服务器,在这个应用中,参数是状态,基于状态的操作便是训练. 在传统的分布式训练框架,如PyTorch中,分布式训练的每个训练进程都维护了一份参数信息,并且都各自计算出一个梯度,进程之间需要交换梯度信息以计算出总梯度和更新后的参数,这就意味着梯度需要被序列化和反序列化以便在进程间传递。使用行动器的架构可以使整个系统中只维护一份参数信息,并且对于同一份参数的更新操作都是串行的。另外,提交参数更新的请求是非阻塞的,参数更新是GPU密集型的任务,因此在提交完后还可以并行地去做CPU密集型的任务,这也是Ray框架异构性的体现。
@ zhihu liadrinz
什么是异构性?
这里的**“异构性”**指的并不是我们常说的 “异构硬件平台”(heterogeneous hardware),例如 GPU + CPU + FPGA 混合这种情况,而是更偏向 Ray 框架在任务调度和执行层面对不同类型计算资源(CPU 与 GPU)的利用方式。
我来帮你拆解一下:
1. 背景:参数更新任务的特点
- 参数更新:通常是 GPU 密集型任务(比如矩阵运算、反向传播、参数加和),需要大量 GPU 算力。
- 请求提交/调度:是 CPU 密集型任务(比如构造请求对象、任务调度、日志、数据预处理)。
传统框架(比如 PyTorch DDP):
- 每个进程都维护一份参数 → 梯度要 序列化/反序列化并跨进程传输。
- 在同步梯度阶段,进程常常需要等待通信完成,CPU 和 GPU 很容易出现 互相等待的情况。
2. Ray 的 Actor 模型带来的不同
- 状态集中管理:Actor 内部保存唯一一份参数状态,更新操作在 Actor 内部完成,不必序列化/反序列化参数 → 节省通信开销。
- 请求非阻塞:训练进程把“更新请求”发给参数服务器 Actor 后就可以立刻返回,不需要等待 GPU 执行更新完成。
3. 这里“异构性”的含义
当文中说 “这也是 Ray 框架异构性的体现” 时,指的是:
- CPU 和 GPU 的工作负载被解耦。
- 训练进程在 CPU 上还能继续做预处理、调度、任务提交等操作,而 GPU 上的 Actor 正在执行更新操作。
- 换句话说,CPU 密集型任务和 GPU 密集型任务可以并行化,不是互相阻塞。
4. 总结
所以这里的“异构性”指的是 Ray 框架对异构计算资源(CPU/GPU)的利用能力,表现为:
- 非阻塞请求 + Actor 内部状态集中管理 → 让 CPU 与 GPU 的任务可以异步并行执行,提升整体效率。
-
Ray采用动态任务图计算模型,其中远程函数和actor方法的执行在他们的输入到达GCS时自动由System Layer触发。下面用论文中的一个例子描述一个计算算图是如何从用户程序中抽象出来的。
这是一个使用Ray Core API构建的伪代码用户程序。
@ray.remote def create_policy(): # 随机初始化策略 return policy @ray.remote(num_gpus=1) class Simulator(object): def __init__(self): # 初始化环境 self.env = Environment() def rollout(self, policy, num_steps): observations = [] observation = self.env.current_state() for _ in range(num_steps): action = policy(observation) observation = self.env.step(action) observations.append(observation) return observations @ray.remote(num_gpus=2) def update_policy(policy, *rollouts): # 更新策略 return policy @ray.remote def train_policy(): # 创建策略 policy_id = create_policy.remote() # 创建10个行动器(仿真器) simulators = [Simulator.remote() for _ in range(10)] # 做100次训练 for _ in range(100): # 每个行动器做一次预演 rollout_ids = [s.rollout.remote(policy_id) for s in simulators] # 使用预演生成的轨迹来更新策略 policy_id = update_policy.remote(policy_id, *rollout_ids) return ray.get(policy_id)可见远端方法
create_policy、update_policy、train_policy与ActorSimulator。首先不考虑Actor,考虑定义数据流与控制流,即箭头指向数据传输方向与箭头指向调用的函数方向。然后定义Actor的状态流,即整体为Actor执行的拓扑函数顺序图。考虑设计计算图如下:
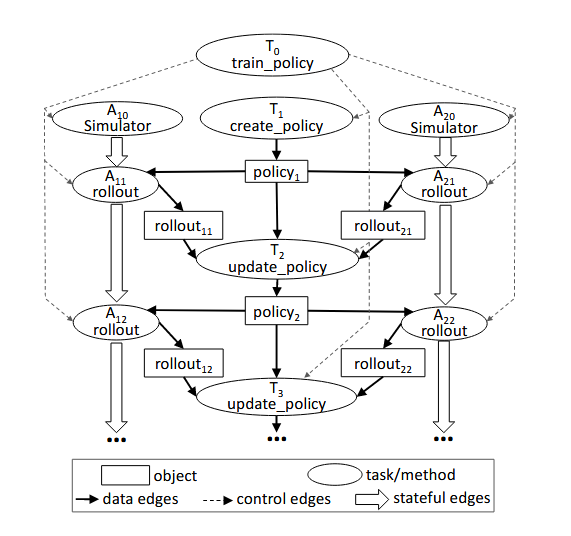
在这里只画出了两个Actor。但不同Simulator之间的过程都是并行的。而同一个模拟器的不同批次的rollout之间之所以是串行的,是因为每次rollout可能改变环境的状态,下一次rollout必须使用前一次rollout结束的状态作为开始状态。
System Layer
-
GCS
GCS设计的初衷是让系统中的各个组件都变得尽可能地无状态,因此GCS维护了一些全局状态:
- 对象表 (Object Table):记录每个对象存在于哪些节点
- 任务表 (Task Table):记录每个任务运行于哪个节点
- 函数表 (Function Table):记录用户进程中定义的远程函数
- 事件日志 (Event Logs):记录任务运行日志
-
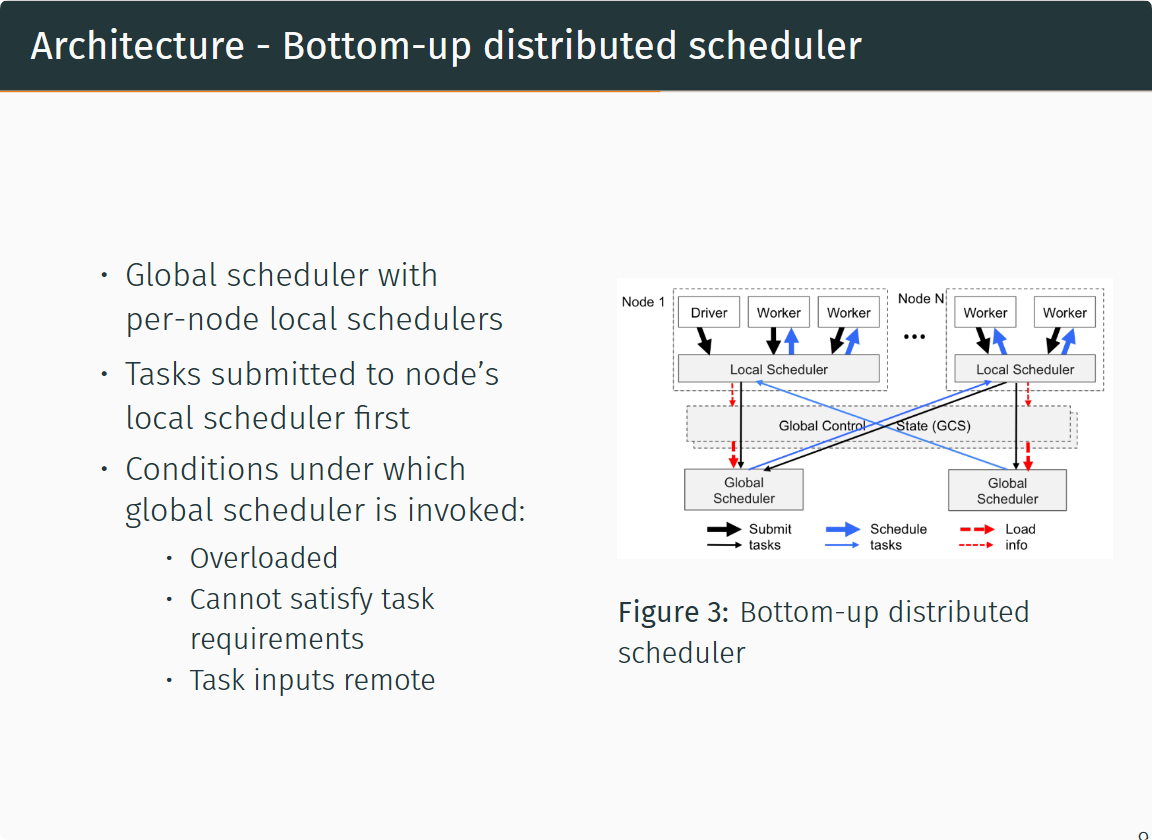
Bottom-up distributed scheduler
Ray中的任务调度器被分为两层,由一个全局调度器和每个节点各自的局部调度器组成。为了避免全局调度器负载过重,在节点创建的任务首先被提交到局部调度器,如果该节点没有过载且节点资源能够满足任务的需求(如GPU的需求),则任务将在本地被调度,否则任务才会被传递到全局调度器,考虑将任务调度到远端。由于Ray首先考虑在本地调度,本地不满足要求才考虑在远端调用,因此这样的调度方式也被称为自底向上的调度。
-
局部性原理的对象存储器
Ray实现了一个内存式的分布式存储系统来存储每个任务的输入和输出。Ray通过内存共享机制在每个节点上实现了一个对象存储器 (Object Store),从而使在同一个节点运行的任务之间不需要拷贝就可以共享数据。当一个任务的输入不在本地时,则会在执行之前将它的输入复制到本地的对象存储器中。同样地,任务总会将输出写入到本地的对象存储器中。这样的复制机制可以减少任务的执行时间,因为任务永远只会从本地对象存储器中读取数据(否则任务不会被调度),并且消除了热数据可能带来的潜在的瓶颈。
注意:GCS中本身并不存放Object,存放的是Object的元数据,数据间的通信并不直接经过GCS,解耦了task dispatch与 task scheduler是GCS,Object Storage designed的main idea。
Putting Everything Together
这里从进程的角度分析
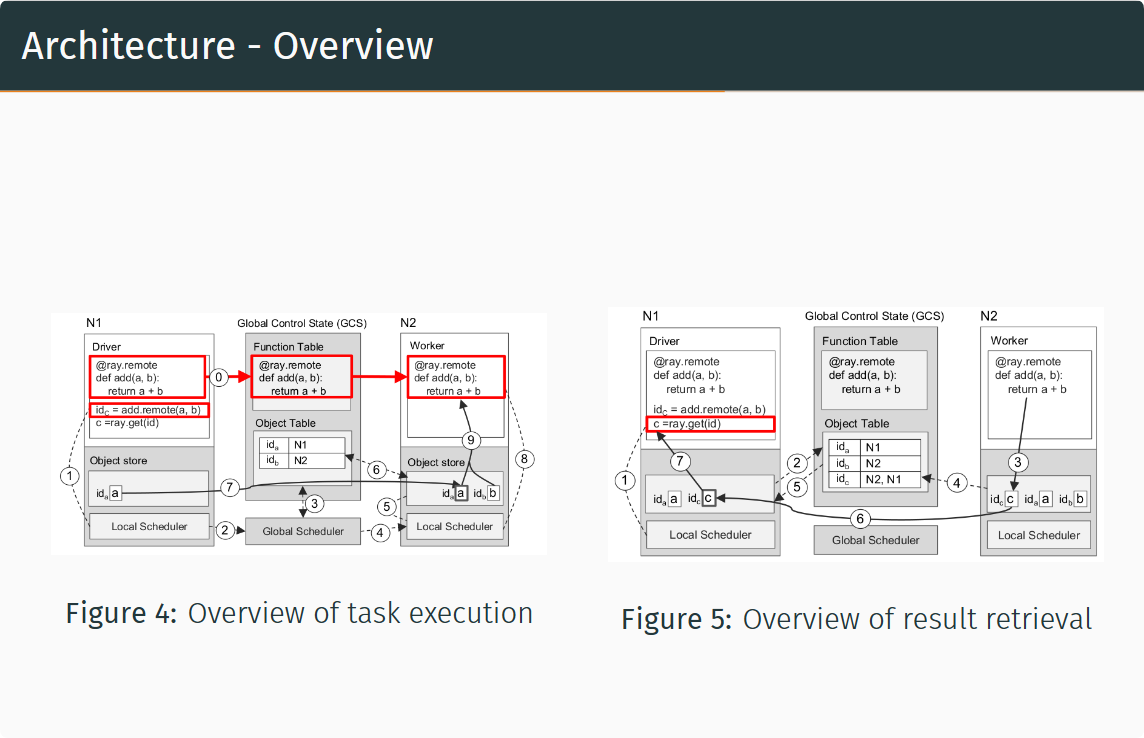
图4描述了任务的定义、提交和执行的过程
- 【定义远程函数】位于$N_1$的用户程序中定义的远程函数add被装载到GCS的函数表中,位于$N_2$的工作器从GCS中读取并装载远程函数add
- 【提交任务】位于$N_1$的用户程序向本地调度器提交add(a, b)的任务
- 【提交任务到全局】本地调度器将任务提交至全局调度器
- 【检查对象表】全局调度器从GCS中找到add任务所需的实参a, b,发现a在$N_1$上,b在$N_2$上(a, b 已在用户程序中事先定义)
- 【执行全局调度】由上一步可知,任务的输入平均地分布在两个节点,因此全局调度器随机选择一个节点进行调度,此处选择了$N_2$
- 【检查任务输入】 的局部调度器检查任务所需的对象是否都在$N_2$的本地对象存储器中
- 【查询缺失输入】 的局部调度器发现任务所需的a不在$N_2$中,在GCS中查找后发现a在$N_1$中
- 【对象复制】将a从$N_1$复制到$N_2$
- 【执行局部调度】在 的工作器上执行add(a, b)的任务
- 【访问对象存储器】add(a, b)访问局部对象存储器中相应的对象
图5描述了获取任务执行结果的的过程
- 【提交get请求】向本地调度器提交ray.get的请求,期望获取add任务执行的返回值
- 【注册回调函数】$N_1$本地没有存储返回值,所以根据返回值对象的引用id_c在GCS的对象表中查询该对象位于哪个节点,假设此时任务没有执行完成,那么对象表中找不到id_c,因此$N_1$的对象存储器会注册一个回调函数,当GCS对象表中出现id_c时触发该回调,将c从对应的节点复制到$N_1$上
- 【任务执行完毕】$N_2$上的add任务执行完成,返回值c被存储到$N_2$的对象存储器中
- 【将对象同步到GCS】$N_2$将c及其引用id_c存入GCS的对象表中
- 【触发回调函数】2中注册的回调函数被触发
- 【执行回调函数】将c从$N_2$复制到$N_1$
- 【返回用户程序】将c返回给用户程序,任务结束
Ray Update Log
2016 年,UC Berkeley 的 RISELab 发布了一个新的分布式计算框架 Ray。
2017 年,发布 Ray 相关论文之后,受到业内的广泛关注,国内主要是蚂蚁集团采用并贡献了 Ray。
2020 年,Ray 发布了 1.0 版本,引入 Placement Group 特性,增加了用户自定义任务编排的灵活性,为后续的 Ray AI Libraries 和 vLLM 等项目提供了基础支持。
2021 年,Ray 发布了 1.5 版本,发布 Ray Data Alpha,弥补了 Ray 在 AI 数据处理和离线推理领域的空白,后续在 AI 数据处理方面得到广泛应用。
2022 年,Ray 发布了 2.0 版本,引入 Ray AIR(Ray AI Runtime)概念,聚焦 AI 生态,使用户能够基于此快速构建 AI 基建。
2023 年,Ray 发布了 2.9 版本,引入 Streaming Generator,原生支持流式推理能力,更好地适配大模型场景。大模型推理引擎 vLLM 基于 Ray Core 及 Ray Serve 构建分布式推理能力,进一步丰富了 Ray 的 AI 生态。
2024 年,Ray 发布了 Ray 2.32 版本,引入 Ray DAG,更好地支持 AI 场景下异构设备间的通信,持续推动 Ray 在分布式计算尤其是 AI 领域的应用和发展。
目前 Ray 最新的版本是 2.42.0。