Ascend C算子开发 Part1基本概念
Ascend C算子开发 Part1基本概念
引言
Ascend C的文档写的并不是很好,如果直接上手会导致许多问题。例如,对于API的调度很有可能会分不清哪一个是最底层的供算子调度的API,哪些是已经定义好的Ascend CL算子。除此之外,还会有例如vscode Warring Lens疯狂报错等问题,这是由于CANN安装的头文件搜索路径导致的。因此,这个领域的学习并不能一味的实践,多看文档,多问已踩过坑的人才是关键。
CANN
CANN(Compute Architecture for Neural Networks,神经网络计算架构)是华为推出的面向AI计算的异构计算架构,专为昇腾(Ascend)系列AI处理器设计,旨在提升AI应用的计算效率与开发便捷性。
其主要开放了三级开发接口:
- 算子开发接口:用于对算子进行开发
- 模型开发接口:用于构建神经网络,构造计算图,例如aclnnop系列算子
- 应用开发接口:第三方lib库开发,比如分配内存,拷贝数据,调用算子。
Ascend硬件架构
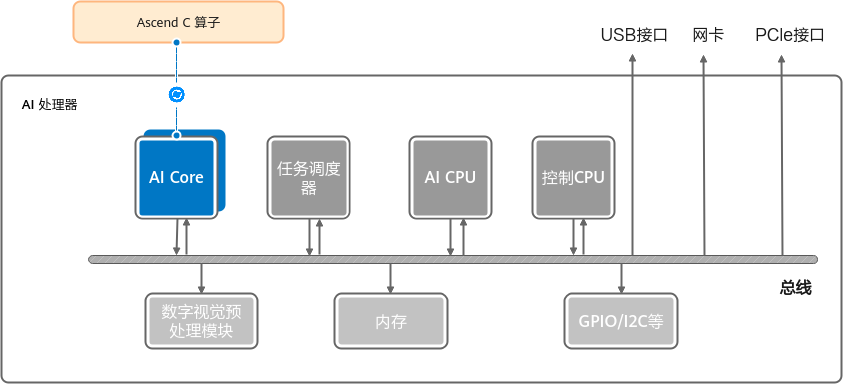
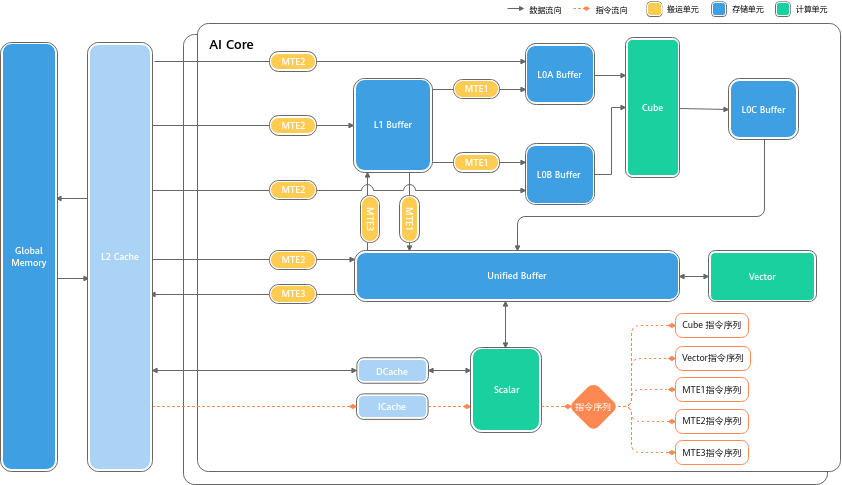
内存层次
Global Memory(GB): 又称HBM,一般是堆叠DRAM架构的,大小在32-80GB范围的device全局内存
L2: 可以通过寄存器值关闭,例如devmem 0x703f70014 32 0xa01bf5(910b),关于缓存,一般认为GB上还有一道Lasest Level Cache(LLC),该缓存为NPU,AICPU共用
Core: 截至2025,Ascend910b将Core分为AICore,AIVector,一般将AICore认为运算密集,AIVector认为控制密集
NPU设计认为HBM的带宽虽然很高,但仍不够用,一般计算将数据搬运至Local Memory(L2Cahce不可用)
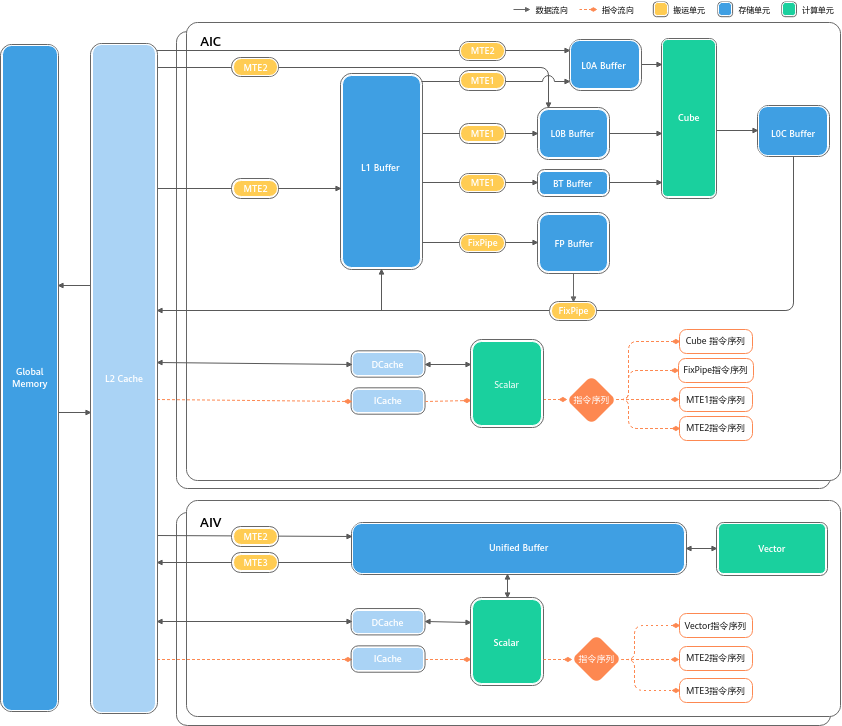
Scalar: 标量计算单元
Vector: 向量计算单元
Cube: 矩阵运算单元
MTE1,2,3:传输单元
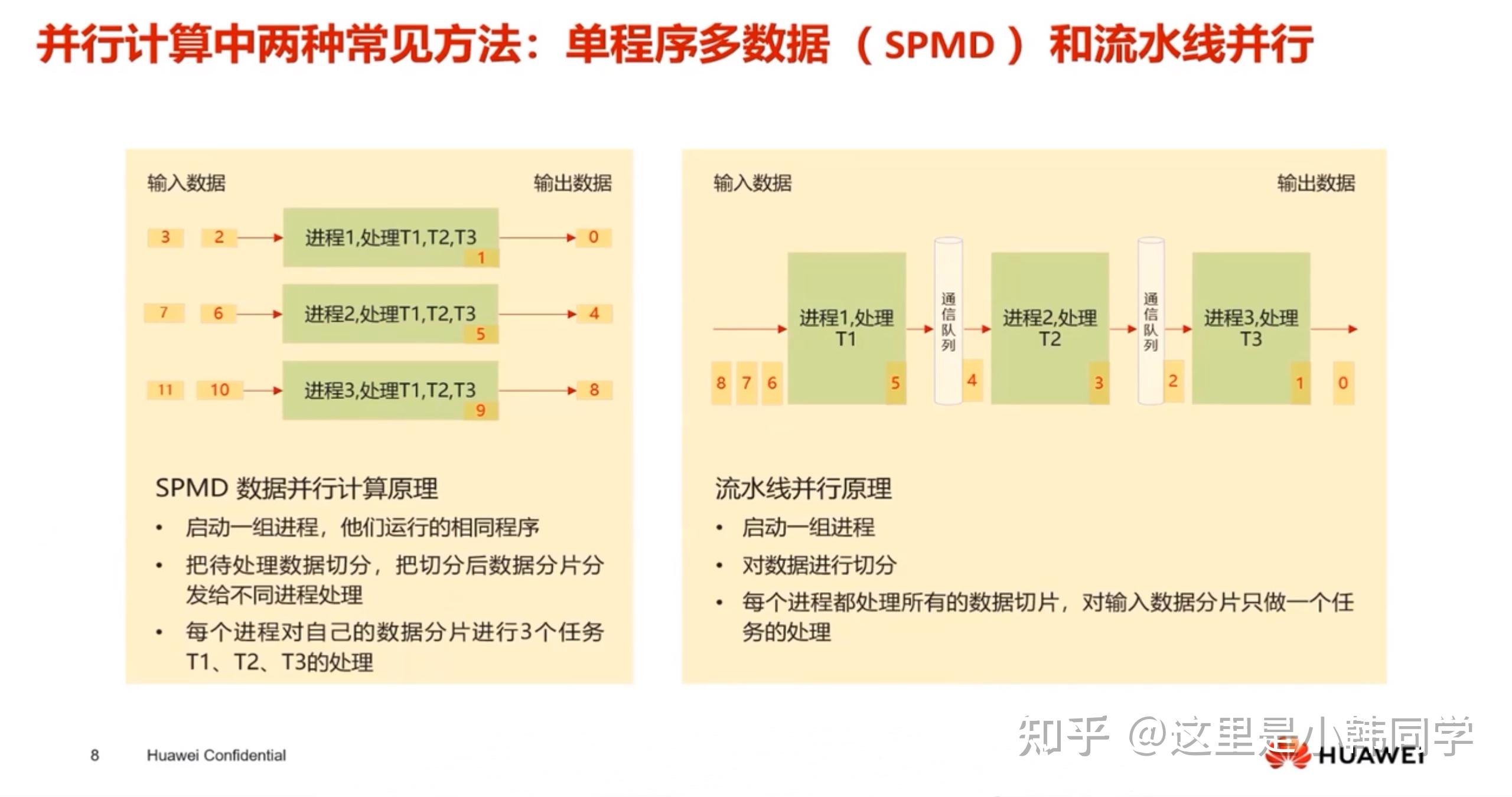
SPMD(Single Program, Multiple Data)
SPMD 是指:同一个程序(Program)在多个处理单元(如CPU核、GPU、AI Core等)上同时运行,但各自操作不同的数据(Data)
计算api示例
abs(src1, dst1, repeatnum, repeatstride, mask, srcblckstr,dst1blckstr)这是一个0级计算api
- 内部SIMD(Single Instruction, Multiple Data)计算是固定32B*8=256B的宽度进行repeat计算
- 指定BlockStride即参5(32B单位)
- 指定RepeatStride即参4(32B单位)和repeatNum即参3
- 指定一个128bits的MASK作用于每个repeat上的128个FP16 element
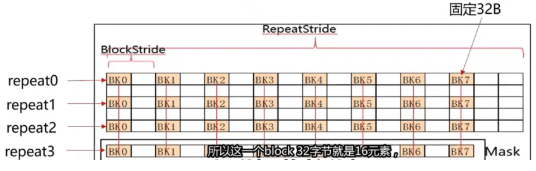
SIMD并行计算原理
- 启动一组线程,他们运行相同的程序
- 把待处理数据切分,把切分后数据分片分发给不同进程处理
- 每个进程对自己的数据分片进行三个任务的处理
多个AIC(ore)共享相同的指令代码,每个核上运行实例的唯一区别是block_idx不同,block_idx是标识进程的唯一属性,cpp中通过GetBlockIdx()获取
并行计算方法
达芬奇 算子 (Ascend C)编程的关键技术难点
- 复杂指令的语义
- 核内buffer的分配,释放,复用
- 多个并行执行单元之间的流水核同步编排在单一线程内实现
- 并行计算,算子的并行切分策略
定义:Ascend C编程就是Cpp加上一组类API编程策略
以matmul为例,指令流水图如下图所示
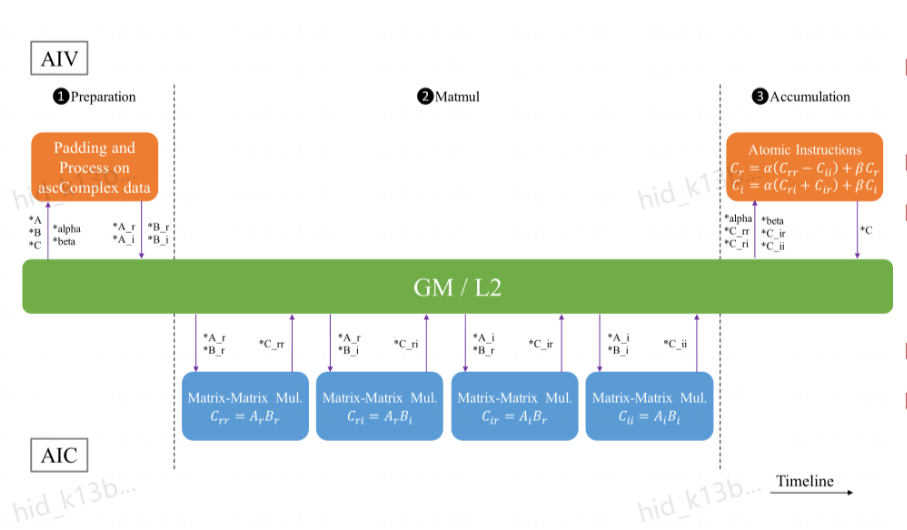
可见整体过程就只有三个过程
- CopyIn
- Process
- CopyOut
基本API
API计算参数都是Tensor类型,Global Tensor和LocalTensor
- 计算API
- 数据搬移类API
- 同步和内存管理API
API分级
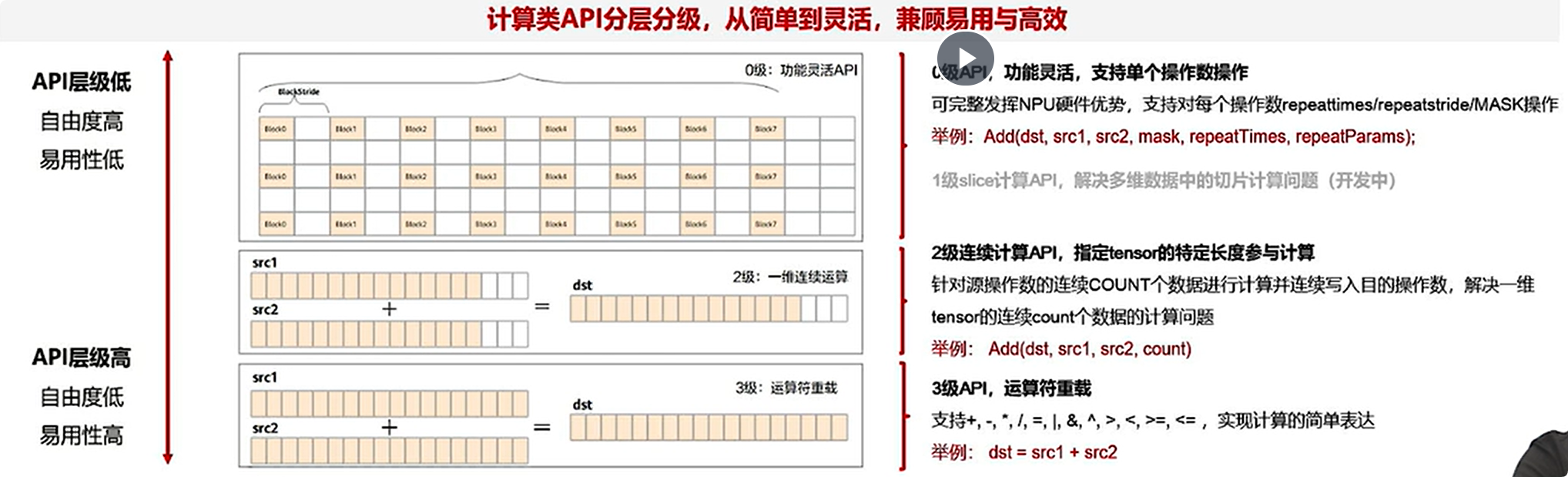
注意,不同LevelAPI对硬件的调度程度不同,例如level0最能调度数据,level3,则具有运算符重载等操作
核函数
核函数(Kernel Function),在昇腾(Ascend)AI处理器和 Ascend C 算子开发语境中,是指在AI Core上执行的核心计算函数,即算子中最耗时、最核心的计算逻辑的实现单元。
在Ascend C中的体现:
在Ascend C中,核函数通常定义为一个 __aicore__ 函数(类CUDA语法),表示该函数将在AI Core上并发执行。
__aicore__
void add_kernel(half* input_a, half* input_b, half* output, int size) {
int idx = get_block_idx() * get_block_dim() + get_thread_idx();
if (idx < size) {
output[idx] = input_a[idx] + input_b[idx];
}
}get_block_idx():获取当前Block ID(对应AI Core ID)get_thread_idx():获取线程ID(在AI Core内用于数据分片)- 实现 SPMD 模式:每个AI Core运行同一核函数,处理数据的不同分片
与通用计算中的“核函数”区别:
| CUDA/OpenCL | GPU上的并行计算函数 |
| Ascend C | AI Core上的高性能计算函数,专为AI计算优化 |
| 机器学习(如SVM) | 指“核技巧”中的数学函数(如RBF核)——完全不同概念 |
⚠️ 在Ascend C上下文中,“核函数”指 执行在AI Core上的计算内核,不是SVM中的核函数。
Summary:__global__ __aicore__ void [kernelname] [argumnet_list]
__global__:标识一个可以被host侧使用<<<...>>>方式调用的核函数,返回值必须为void,使用__aicore__标识的核函数在设备AIC上执行
指数入参的统一类型是__gm__ uint8_t* ,一般宏定义为GM_ADDR。__gm__表示该指针变量驻留在内存空间上。
- 核函数必须具有void返回类型
- 仅支持入参为指针类型或c/cpp内置的数据类型(Primitive Data Type),eg:
half* so,float* s1,int32_t c - 默认
#define GM_ADDR __gm__ uint8_t* __restrict__
核函数调用
只有NPU模式下才能调用核函数
核函数只能使用内核调用符<<<...>>>这种语法形式,来规定和函数的执行配置。
kernel_name<<<blockDim, l2ctrl, stream>>>(argument list);-
blockDim,规定了核函数将会在几个核上运行,每个执行该核函数的核将会被分配一个逻辑ID,表现为内置变量
block_id,编号从0开始,可谓不同的逻辑核定义不同的行为,可在算子实现中使用GetBlockIdx()函数获得。 -
I2ctrl,保留参数
-
stream,类型为aclrtStream,Stream是一个任务对罗列,程序通过Stream来管理任务的并行
编程范式
编程范式把算子内部的处理程序分为多个流水任务(Stage),以Tensor座位数据载体,Quene进行任务间的通信与同步,以Pipe管理任务见的通信内存。
典型计算范式
- 矢量编程范式
CopyIn Compute CopyOut - 矩阵编程范式
CopyIn Split Compute Aggregate CopyOut - 复杂任务范式,通过组合实现复杂计算数据流
附录
需要掌握使用MindStudio工具链中的msprof,msopgen,mindinsight工具。
例如msopgen工具生成的目录结构对该章内容很有帮助。
对于以下自定义算子的原型定义文件
[
{
"op": "SinhCustom",
"language":"cpp",
"input_desc": [
{
"name": "x",
"param_type": "required",
"format": [
"ND"
],
"type": [
"fp16"
]
}
],
"output_desc": [
{
"name": "y",
"param_type": "required",
"format": [
"ND"
],
"type": [
"fp16"
]
}
]
}
]使用以下命令
./msopgen gen -i ${JSON_FILE_PATH}/sinh.json -f pytorch -c ai_core-ascend910 -lan cpp -out ${OUTPUT_PATH}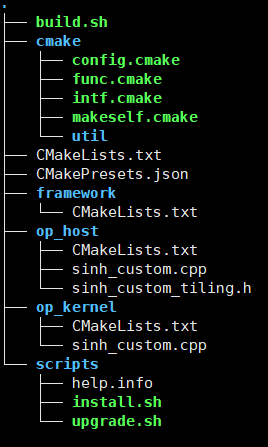
该结构以及相关文件能够让初学者更深入的理解CANN与算子的调用逻辑。

REF
- Huawei docs (W3)
- [【CANN训练营】Ascend算子开发入门笔记-云社区-华为云](https://bbs.huaweicloud.com/blogs/412456#:~:text=0级丰富功能计算API,可以完整发挥硬件优势的计算API,该功能可以充分发挥CANN系列芯片的强大指令%2C支持对每个操作数的repeattimes%2Crepetstride%2CMASK的操作。,调用类似:Add (dst%2Csrc1%2Csrc2%2CrepeatTimes%2CrepeatParams)%3B)
- 基本架构-CANN社区版8.2.RC1.alpha001-昇腾社区
- (99+ 封私信 / 80 条消息) Ascend C算子开发(入门)笔记一:基础概念 - 知乎
- GEMM类算子调优-昇腾社区
- Ascend C算子开发(入门)-昇腾社区
- Ascend C简介-CANN社区版8.2.RC1.alpha001-昇腾社区